Disclaimer
Este post é uma implementação em R do código já desenvolvido em Python e apresentado neste post: A Neural Implementation of NBSVM in Keras - Escrito por: Arun Maya.
Apesar do nome NBSVM, não trabalharemos com o SVM (support vector machines) neste post. O nome do modelo faz referência ao paper “Baselines and Bigrams: Simple, Good Sentiment and Topic Classification” escrito por Sida Wang e Christopher Manning. Os autores testam o modelo SVM com Naive Bayes features que são criadas utilizando o log das razões de contagem. Contudo, costuma-se também usar o modelo de regressão logística no lugar do SVM. Por exemplo: NB-SVM strong linear baseline.
Pacotes
library(text2vec)
library(tidyverse)
library(keras)Preparando os Dados
Os dados podem ser baixados neste link.
Os arquivos estão separados em pastas distintas por conjunto (treino e teste) e sentimento (negativo e positivo). O Código abaixo prepara os dados:
imdb_path <- '../../dados/aclImdb'
train <- map_df(c("neg", "pos"), ~ {
idx <- .x
arquivos <- list.files(
file.path(imdb_path, "train", idx),
full.names = TRUE
)
map_df(arquivos, ~ {
tibble(
review = read_lines(.x)
) %>%
mutate(sentiment = idx)
})
}) %>%
# coloca em ordem aleatória
sample_frac(1)
head(train)
# A tibble: 6 x 2
review sentiment
<chr> <chr>
1 "Predictable, hackneyed & poorly written. Foolishly I rea… neg
2 "Pointless boring film with charismatic Mercurio complete… neg
3 "OK, the box looks promising. Whoopi Goldberg standing ne… neg
4 "Awful, awful, awful.<br /><br />A condescending remark a… neg
5 "The night of the prom: the most important night to any s… neg
6 "SERIES THREE- BLACKADDER THE THIRD \" If you want someth… pos
test <- map_df(c("neg", "pos"), ~{
idx <- .x
arquivos <- list.files(file.path(imdb_path, "test", idx), full.names = TRUE)
map_df(arquivos, ~{
tibble(
review = read_lines(.x)
) %>%
mutate(sentiment = idx)
})
})
head(test)
# A tibble: 6 x 2
review sentiment
<chr> <chr>
1 "Once again Mr. Costner has dragged out a movie for far l… neg
2 "This is a pale imitation of 'Officer and a Gentleman.' T… neg
3 "Years ago, when DARLING LILI played on TV, it was always… neg
4 "I was looking forward to this movie. Trustworthy actors,… neg
5 "First of all, I would like to say that I am a fan of all… neg
6 "This is an example of why the majority of action films a… neg
# Adiciona o ID e limpa os textos para deixar apenas letras
train <- train %>%
mutate(
id = paste0("train_", 1:n())
)
test <- test %>%
mutate(
id = paste0("test_", 1:n())
)
dim(train)
[1] 25000 3
dim(test)
[1] 25000 3Definindo o vocabulário
O código abaixo cria o nosso vocabulário. Isto é, o conjunto de termos que serão considerados pelo modelo. As stopwords, que são palavras que não possuem um significado direto, não foram removidas (de propósito) e consideramos unigramas, bigramas e trigramas. O vocabulário foi limitado a 800.000 termos.
vocabulario <- itoken(
train$review,
preprocessor = tolower,
tokenizer = word_tokenizer,
id = train$id,
progressbar = FALSE
) %>%
create_vocabulary(
it = .,
ngram = c(1, 3)
) %>%
prune_vocabulary(
vocabulary = .,
vocab_term_max = 800000
)
text_vectorizer <- vocab_vectorizer(vocabulary = vocabulario)
vocabulario
Number of docs: 25000
0 stopwords: ...
ngram_min = 1; ngram_max = 3
Vocabulary:
term term_count doc_count
1: the 336179 24792
2: and 164061 24164
3: a 162738 24174
4: of 145848 23727
5: to 135695 23475
---
799996: parnell_was 2 2
799997: he_was_missing 2 2
799998: that_cypher 2 1
799999: 20_years_that 2 2
800000: dicaprio_as 2 2Textos para IDs
Nesta parte, iremos converter os nossos textos em matrizes nas quais cada linha representará um texto (um review) e haverá N (igual ao valor definido no objeto max_len no nosso código) colunas que identificam os termos que aparecem naquele texto. Por exemplo, a primera coluna irá guardar o ID (número de identificação) do primeiro termo, na ordem do vocacabulário, que aparece em cada texto. A segunda coluna, por sua vez, traz o ID do segundo termo. Se o número de termos no texto for inferior a N, utiliza-se o ID 0 nas colunas restantes.
text_to_ids <- function(textos, vocabulario, max_len = 128, text_vectorizer) {
tokens <- itoken(
textos,
preprocessor = tolower,
tokenizer = word_tokenizer,
id = 1:length(textos),
progressbar = FALSE
)
dtm <- create_dtm(
it = tokens,
vectorizer = text_vectorizer,
type = 'dgCMatrix'
)
dtm <- 1 * (dtm > 0)
TmpX <- as(dtm, "dgTMatrix")
dtm_df <- data.frame(matrix(c(TmpX@i + 1, TmpX@j + 1), ncol = 2)) %>%
arrange(X1) %>%
group_by(X1) %>%
mutate(n = 1:n()) %>%
ungroup() %>%
filter(n <= max_len)
X <- crossing(
X1 = unique(dtm_df$X1),
n = 1:max_len
) %>%
left_join(dtm_df, by = c("X1", "n")) %>%
replace_na(list(X2 = 0)) %>%
select(X1, X2)
X <- matrix(X$X2, ncol = max_len, byrow = TRUE)
return(X)
}
max_len <- 2048
# Exemplo
text_to_ids(c("awesome movie"), vocabulario, max_len, text_vectorizer)[, 1:10]
[1] 18 2188 55038 0 0 0 0 0 0 0
# Criando input para os dados de treinamento e teste
xtrain <- text_to_ids(train$review, vocabulario, max_len, text_vectorizer)
xtest <- text_to_ids(test$review, vocabulario, max_len, text_vectorizer)
xtrain[33:40, 56:63]
[,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8]
[1,] 144 147 148 150 156 161 163 167
[2,] 310 311 312 321 326 357 359 387
[3,] 69 71 72 74 75 81 82 85
[4,] 602 629 644 737 784 806 825 889
[5,] 241436 273065 317913 380640 401286 403465 460155 471071
[6,] 81 83 87 88 95 102 103 104
[7,] 885 925 1057 1112 1164 1205 1317 1328
[8,] 103 104 105 108 113 114 120 121Calculando as razões de contagem
Neste trecho, calculamos a chance de cada palavra aparecer em uma determinada classe (positivo ou negativo) e computamos o log da razão dessas chances. Essas seriam as features (o valor imputado para cada termo) que deveriam ser utilizadas no modelo SVM como inicialmente proposto em “Baselines and Bigrams: Simple, Good Sentiment and Topic Classification”.
train_dtm <- itoken(
train$review,
preprocessor = tolower,
tokenizer = word_tokenizer,
id = train$id,
progressbar = FALSE
) %>%
create_dtm(
it = .,
vectorizer = text_vectorizer,
type = 'dgCMatrix'
)
p <- Matrix::colSums(train_dtm[train$sentiment == "pos", ])
q <- Matrix::colSums(train_dtm[train$sentiment == "neg", ])
p <- (p + 1) / (sum(train$sentiment == "pos") + 1)
q <- (q + 1) / (sum(train$sentiment == "neg") + 1)
nb_ratio <- log(p / q)
nb_ratio[1:4]
the and a of
0.05850303 0.18788121 0.05270975 0.10774897 Por fim, passamos esse vetor para uma matriz que será utilizada para alimentar um camada de embeddings do nosso modelo:
# adiciona-se o "pad" ao vocabulário
# Tamanho do Vocabulário: 800.001
vocab_size <- nrow(vocabulario) + 1
# O pad (ID 0) fica com a razão definida em 0.
embedding_matrix <- matrix(0, nrow = vocab_size, ncol = 1)
embedding_matrix[-1, ] <- nb_ratioDefinindo o modelo no Keras
O nosso modelo contará com embeddings. De forma simplificada, os embeddings são utilizados para representar de forma densa, por exemplo, uma palavra. No modelo de bag-of-words, um termo é representado por um vetor de tamanho igual ao vocabulário, no qual apenas uma coluna é diferente de zero. Quando se utiliza embeddings, pode-se trabalhar com representações consideravelmente menores. Por exemplo, os termos podem ser representados por um vetor de tamanho 100. Ou seja, 100 números representam uma determinada palavra.
No nosso modelo, cada palavra será representada pelo seu valor no vetor nb_ratio. Isto é, utilizaremos um vetor de tamanho 1 para representar cada palavra do nosso vocabulário. Os valores desse embeddings estarão fixos durante o treinamento.
Adicionalmente, utilizaremos um segundo embeddings que representariam os coeficientes de uma regressão logística.
Por fim, computamos o produto escalar (dot product) entre esses dois embeddings e passamos o resultado para uma função ativação sigmoid.
Por exemplo, suponha que o texto contenha as palavras “casa”, “cachorro” e “gato”. Os embeddings seriam os seguintes:
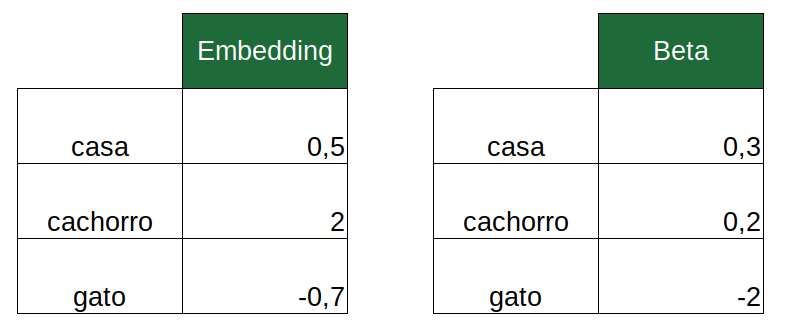
O produto escalar resultante é:
\[0,5 \times 0,3 + 2 \times 0,2 - 0,7 \times -2 = 1,95\]
Este número resultante será passado para uma camada densa com função de ativação sigmoid:
\[\frac{1}{1 + \exp{\left(-1,95\right)}}\]
Assim, obtemos um número entre 0 e 1 que será a probabilidade da classe 1 (que será definida como a classe “positivo”).
O código abaixo define nosso modelo utilizando o Keras.
cria_modelo <- function(lr = 0.001) {
input <- layer_input(shape = max_len)
emb_out <- input %>%
layer_embedding(
input_dim = vocab_size,
output_dim = 1,
input_length = max_len,
weights = list(embedding_matrix),
trainable = FALSE
)
beta <- input %>%
layer_embedding(
input_dim = vocab_size,
output_dim = 1,
embeddings_initializer = "glorot_normal",
input_length = max_len,
)
out <- layer_dot(
list(emb_out, beta),
axes = 1
) %>%
layer_flatten() %>%
layer_activation("sigmoid")
model <- keras_model(
input = input,
out = out
)
model %>%
compile(
optimizer = optimizer_adam(lr = lr),
loss = "binary_crossentropy",
metrics = list("accuracy")
)
return(model)
}
model <- cria_modelo(lr = 0.001)
model
Model
Model: "model"
______________________________________________________________________
Layer (type) Output Shape Param # Connected to
======================================================================
input_1 (InputLayer) [(None, 2048)] 0
______________________________________________________________________
embedding (Embedding) (None, 2048, 1 800001 input_1[0][0]
______________________________________________________________________
embedding_1 (Embedding (None, 2048, 1 800001 input_1[0][0]
______________________________________________________________________
dot (Dot) (None, 1, 1) 0 embedding[0][0]
embedding_1[0][0]
______________________________________________________________________
flatten (Flatten) (None, 1) 0 dot[0][0]
______________________________________________________________________
activation (Activation (None, 1) 0 flatten[0][0]
======================================================================
Total params: 1,600,002
Trainable params: 800,001
Non-trainable params: 800,001
______________________________________________________________________Treinando e Avaliando o Modelo
Abaixo, criamos as matrizes de target:
ytrain <- train %>%
select(sentiment) %>%
mutate(sentiment = ifelse(sentiment == "pos", 1, 0)) %>%
data.matrix()
ytest <- test %>%
select(sentiment) %>%
mutate(sentiment = ifelse(sentiment == "pos", 1, 0)) %>%
data.matrix()
head(ytrain)
sentiment
[1,] 0
[2,] 0
[3,] 0
[4,] 0
[5,] 0
[6,] 1Vamos agora treinar o modelo e avaliar na base de teste:
model %>%
fit(
xtrain, ytrain,
batch_size = 32,
epochs = 3,
validation_data = list(xtest, ytest)
)
avaliacao_test <- model %>% evaluate(xtest, ytest)
avaliacao_test
$loss
[1] 0.215041
$accuracy
[1] 0.9232O modelo atingiu a acurácia de 92,3%.
É isso que temos para hoje! Qualquer dúvida, crítica ou sugestão é só deixar nos comentários!