Introdução
Neste post, iremos criar um simples classificador de raças de cães no R. Apesar do número de imagens ser relativamente pequeno (10222 imagens), é possível usar modelos pré-treinados e extrair features que nos permitirão treinar o classificador.
O pacote Keras será usado. O classificador alcançou uma acurácia de 91% no conjunto de validação. Para os dados de testes, é possível apenas o obter o logloss ao submeter as predições no Kaggle.
Adicionalmente, nós tentamos implementar alguns callbacks que contém técnicas que são ensinadas no curso fastai course.
Pacotes
Estes são os pacotes que serão usados neste post:
library(keras)
library(tidyverse)
library(rsample)
library(glue)
library(magick)
library(patchwork)Dados
Os dados utilizados para treinar o classificador estão no disponíveis no Kaggle. Você pode baixar diretamente na página da competição. Se você possui a biblioteca Python da API do Kaggle configurada no seu computador, é possível baixar os dados usando esse comando:
kaggle competitions download -c dog-breed-identificationUma vez que você tenha baixado os dados e os arquivos tenham sido dezipados, a sua pasta de dados deverá ter os seguintes arquivos/pastas:
# Path to the main folder
data_path <- 'dog_breeds'
list.files(data_path)
[1] "labels.csv" "test" "train" Aqui, lemos o arquivo com o rótulo de cada imagem:
labels <- read_csv(file.path(data_path, 'labels.csv'))
glimpse(labels)
Observations: 10,222
Variables: 2
$ id <chr> "000bec180eb18c7604dcecc8fe0dba07", "001513dfcb2ffa...
$ breed <chr> "boston_bull", "dingo", "pekinese", "bluetick", "go...O número total de classes é igual a 120:
length(unique(labels$breed))
[1] 120Vamos visualizar algumas imagens:
show_image <- function(id, breed){
file.path(data_path, "train", glue("{id}.jpg")) %>%
image_read() %>%
image_ggplot() +
labs(title = breed) +
theme(
plot.title = element_text(hjust = 0.5)
)
}
set.seed(3011)
labels %>%
sample_n(4) %>%
pmap(., show_image) %>%
wrap_plots()
Separação dos dados em treino e validação
O código abaixo cria dois data.frames, o primeiro será utilizado para treinamento e o segundo para validação. 90% das imagens que estão na pasta train serão utilizadas para treinar o modelo. As imagens restantes serão utilizadas para validar o modelo.
set.seed(93891)
labels <- initial_split(labels, prop = 0.9,strata = "breed")
train_data <- training(labels)
valid_data <- testing(labels)Extraindo as features a partir de modelos pré-treinados
Para treinar um classificador de imagens, existem três estratégicas básicas:
Treinar um novo modelo do zero;
Usar um modelo pré-treinado e realizar um ajuste (fine tuning) em algumas camadas desse modelo, além acoplar umas camadas adicionais;
Extrair as features a partir da base convolucional do modelo e treinar um novo classificador usando essas features.
Nós usaremos a terceira abordagem. Esta estratégia é indicada para quando a base de treinamento é pequena (um pequeno número de imagens por classe) e as imagens que serão utilizadas são de alguma forme similares a imagens que foram usadas no treinamento do modelo pré-treinado (veja aqui. Como os modelos pré-treinados que serão utilizados foram treinados em uma base que possui imagens de cachorros, vamos assumir que esses modelos podem servir de base para o nosso novo classificador.
Serão combinadas features de dois modelos: Xception e Inception-ResNet v2. Ambos os modelos foram treinados utilizando imagens da base ImageNet. Para criar os objetos com esses dois modelos, podemos executar o código abaixo:
xception_model <- application_xception(
include_top = FALSE,
weights = 'imagenet',
input_shape = c(299, 299, 3),
pooling = 'avg'
)
inception_model <- application_inception_resnet_v2(
include_top = FALSE,
weights = 'imagenet',
input_shape = c(299, 299, 3),
pooling = 'avg'
)No próximo passo, nós vamos criar os “geradores de imagens”. Isto é, objetos que irão prover lotes de imagens que serão preprocessadas e usadas como input no modelo base. Como saída, serão geradas as features que serão utilizadas posteriormente como inputs no classificador de raças que iremos treinar.
Para o gerador de imagens de treinamento, vamos utilizar uma técnica chamada de aumento de dados (data augmentation), que consiste em alterar as imagens originais na tentativa de aumentar o tamanho da base que será usada no treinamento. Em regra, esse método ajuda o modelo a generalizar mais, principalmente quando temos poucas imagens para cada classe.
Fazemos o mesmo para a validação, mas não utilizaremos o aumento de dados.
Agora, vamos definir a função que irá extrair de fato as features. Esta função tem dois argumentos: um gerador de imagens e o número de batches que serão processados. Como definimos acima, cada batch tem 16 imagens. A função retorna uma matriz de inputs e uma matriz de targets.
Primeiro vamos extrair as features das imagens de treinamento. No vamos criar uma uma matriz de input com 18400 observações, ou seja, o dobro do número de imagens que estão listadas em train_data (9200). Como estamos alterando as imagens aleatoriamente, nenhuma imagem será de fato repetida.
Treinando o classificador
Após a extração das features, iremos treinar o classificador que terá como input as 3584 variáveis obtidas e, como output, um vetor de probabilidades para cada uma das 120 classes. A função create_model(), como o nome diz, cria o nosso modelo.
create_model <- function(lr = 1e-3){
model <- keras_model_sequential()
model %>%
layer_dropout(0.5, input_shape = ncol(xtrain)) %>%
layer_dense(units = 120, activation = 'softmax')
model %>%
compile(optimizer = optimizer_adam(lr = lr),
loss = 'categorical_crossentropy',
metrics = "accuracy")
return(model)
}Para a escolher a learning rate, vamos usar um callback que foi inspirado (isto é, uma tentativa de replicação) na biblioteca fastai. Vamos setar uma taxa mínima e uma máxima. O treinamento irá começar com a menor taxa e, após cada iteração, a learning rate será atualizada em direção ao seu valor máximo. A taxa será escolhida observando os resultados. Indica-se escolher uma taxa na qual a função de perda esteja decrescendo, mas não esteja no seu mínimo.
model <- create_model()
model
Model
______________________________________________________________________
Layer (type) Output Shape Param #
======================================================================
dropout_1 (Dropout) (None, 3584) 0
______________________________________________________________________
dense_1 (Dense) (None, 120) 430200
======================================================================
Total params: 430,200
Trainable params: 430,200
Non-trainable params: 0
______________________________________________________________________
batch_size <- 256
lrf <- lr_finder$new(
min_lr = 1e-5,
max_lr = 1,
step_size = ceiling(nrow(xtrain)/batch_size)
)
history <- model %>%
fit(
xtrain, ytrain,
batch_size = batch_size,
epochs = 1,
validation_data = list(xvalid, yvalid),
callbacks = list(lrf)
)
lrf$lr_plot()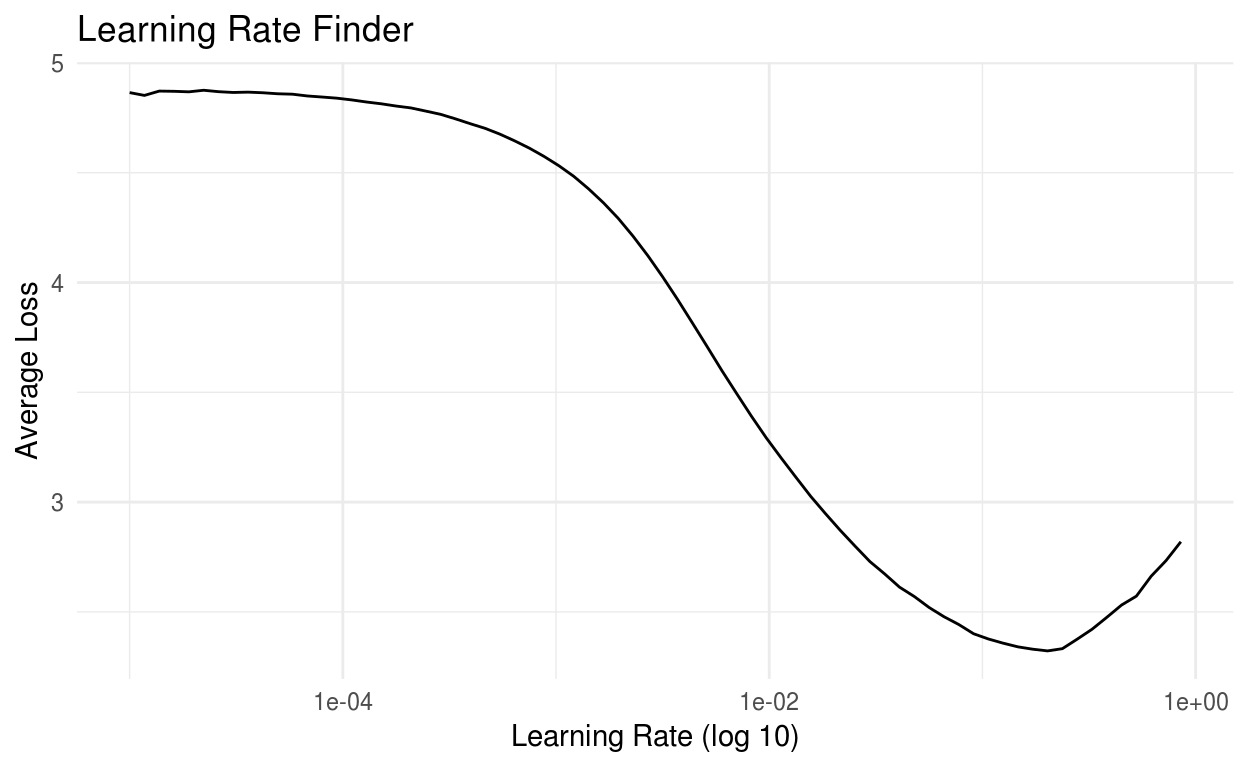
Olhando a figura abaixo, um valor possível seria 0.01. No entanto, setando a learning rate para 0.001, foram obtidos melhores resultados.
Adicionalmente, os autores do fastai indicam a utilização do método conhecido como one cycle policy no momento do treinamento do modelo. Como otimizador, eles usam o AdamW. Entretanto, este otimizador não está disponível no keras por default. Assim, iremos utilizar o Adam. Para detalhes sobre o one cycle policy, eu recomendo este post1.
ocl <- one_cycle_learn$new(
max_lr = 1e-3,
div_factor = 25,
pct_start = 0.5,
n_train = nrow(xtrain),
batch_size = batch_size,
epochs = 10
)
model <- create_model(lr = 1e-3)
history <- model %>%
fit(
xtrain, ytrain,
batch_size = batch_size,
epochs = 10,
validation_data = list(xvalid, yvalid),
verbose = 1,
callbacks = list(ocl)
)Na figura abaixo, é possível ver como a learning rate e o parâmetro beta_1 variam durante o treinamento.
lr_plot <- ocl$history %>%
ggplot(aes(x = iterations, y = lr)) +
geom_line() +
labs(
y = "Learning Rate",
x = "Iteration"
) +
theme_minimal()
momentum_plot <- ocl$history %>%
ggplot(aes(x = iterations, y = beta_1)) +
geom_line() +
labs(
y = "beta_1",
x = "Iteration"
) +
theme_minimal()
lr_plot / momentum_plot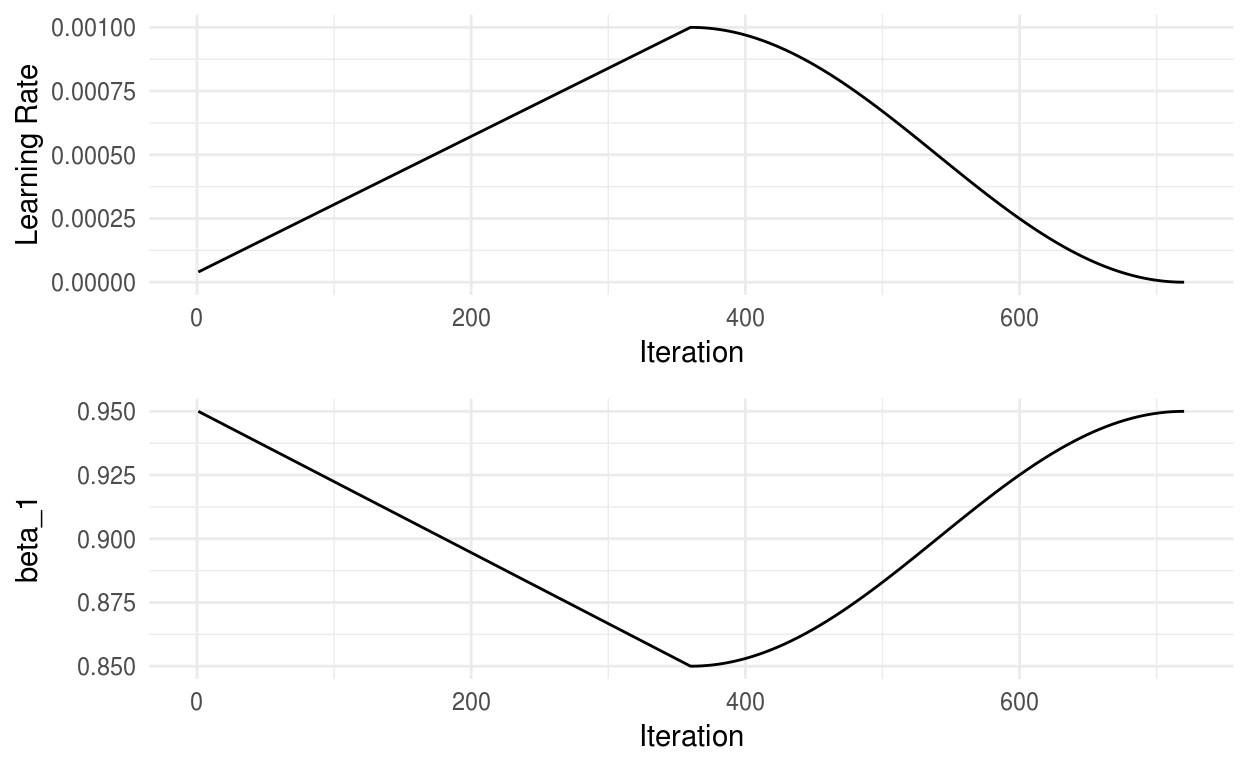
O gráfico com os valores da função de perda e da acurácia para as bases de treino e validação:
plot(history) +
theme_minimal()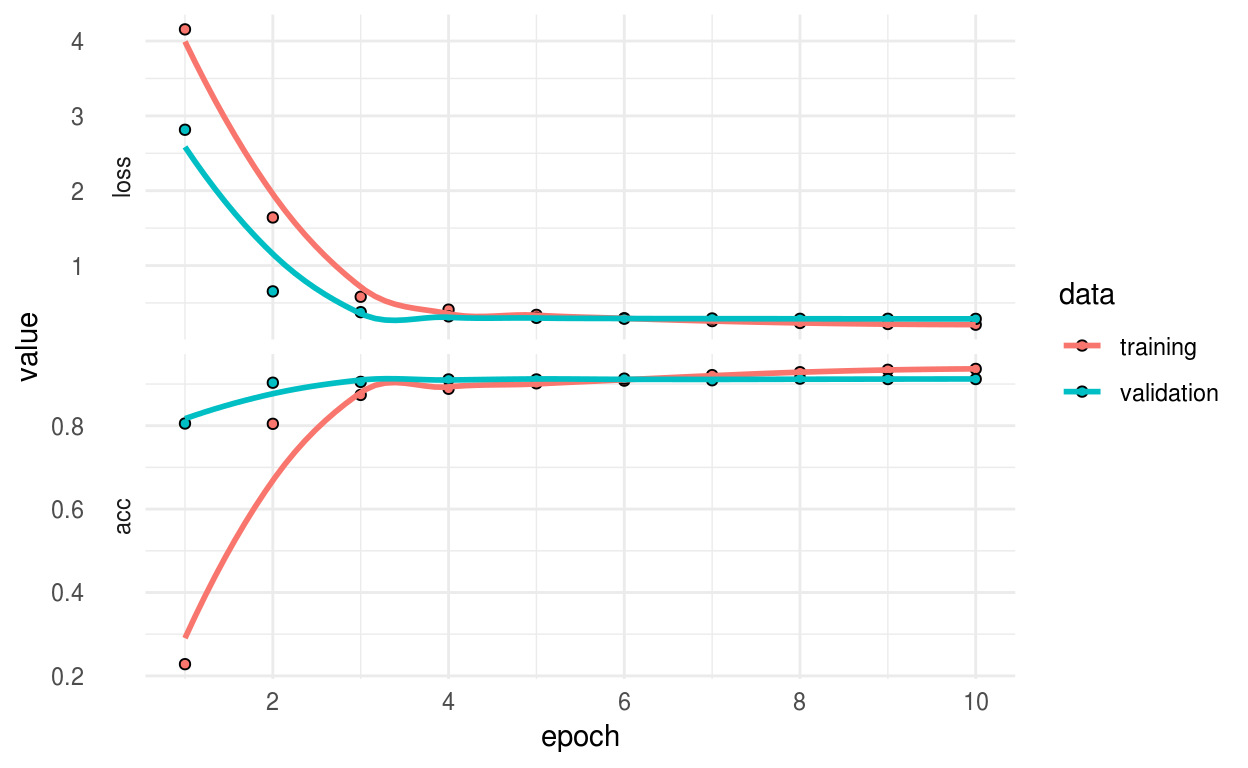
O score final para o conjunto de validação:
evaluate(model, xvalid, yvalid)
$loss
[1] 0.2869113
$acc
[1] 0.9119374Predições para o conjunto de teste
Por fim, vamos gerar as predições para a base de teste. Para usar a função predict_generator(), é necessário criar um gerador que preprocesse as imagens e retorne matrizes no mesmo formato que foi usado no treinamento do modelo. A função custom_generator() faz esse trabalho para a gente.
test_files <- data.frame(
id = list.files(file.path(data_path, 'test')),
breed = NA,
stringsAsFactors = FALSE
)
test_gen <- image_data_generator()
test_gen <- test_gen$flow_from_dataframe(
dataframe = test_files,
directory = file.path(data_path, 'test'),
x_col = 'id',
y_col = 'breed',
has_ext = TRUE,
target_size = c(299L, 299L),
shuffle = FALSE,
class_mode = NULL,
batch_size = 8L
)
custom_generator <- function(test_gen){
function(){
data <- generator_next(test_gen)
input <- data
if(!is.null(test_gen$class_mode)){
input <- data[[1]]
y <- data[[2]]
}
x1 <- input %>%
xception_preprocess_input() %>%
predict(xception_model, .)
x2 <- input %>%
inception_resnet_v2_preprocess_input() %>%
predict(inception_model, .)
out <- list(cbind(x1, x2))
if(!is.null(test_gen$class_mode)){
out[[2]] <- y
}
out
}
}Agora vamos criar o gerador e realizar as predições utilizando a função predict_generator():
test_generator <- custom_generator(test_gen)
test_preds <- predict_generator(model,
test_generator,
steps = ceiling(test_gen$n/test_gen$batch_size),
verbose = 1) %>%
as.data.frame()
names(test_preds) <- classes
test_preds <- test_files %>%
mutate(id = str_sub(id, start = 1, end = -5)) %>%
select(id) %>%
bind_cols(test_preds)
dim(test_preds)
[1] 10357 121Funções Auxiliares
O código para o callback do one cycle policy é inspirado por este repositório. Infelizmente, eu perdi o link original do repositório no qual eu me inspirei para escrever o callback para learning rate finder. =(
Learning Rate Finder
lr_finder <- R6::R6Class("lrFinder",
inherit = KerasCallback,
public = list(
min_lr = NULL,
max_lr = NULL,
beta = NULL,
step_size = NULL,
iteration = 0,
lr_mult = 0,
best_loss = 0,
avg_loss = 0,
history = data.frame(),
initialize = function(min_lr = 1e-5,
max_lr = 1e-2,
step_size = NULL,
beta = 0.98){
self$min_lr <- min_lr
self$max_lr <- max_lr
self$step_size <- step_size
self$beta <- beta
},
lr_plot = function(){
ggplot(self$history, aes(x = lr, y = avg_loss)) +
geom_line() +
scale_x_log10() +
labs(
y = "Average Loss",
x = "Learning Rate (log 10)",
title = "Learning Rate Finder"
) +
theme_minimal()
},
clr = function(){
self$lr_mult <- (self$max_lr / self$min_lr)^(1/self$step_size)
self$lr_mult
},
on_train_begin = function(logs = list()){
k_set_value(self$model$optimizer$lr, self$min_lr)
},
on_batch_end = function(batch, logs = list()){
self$iteration <- self$iteration + 1
loss <- logs[["loss"]]
self$avg_loss <- self$beta * self$avg_loss + (1-self$beta) * loss
smoothed_loss <- self$avg_loss/(1-self$beta^self$iteration)
if(self$iteration > 1 & smoothed_loss > self$best_loss * 4){
self$model$stop_training <- TRUE
}
if(smoothed_loss < self$best_loss | self$iteration == 1){
self$best_loss <- smoothed_loss
}
lr = k_get_value(self$model$optimizer$lr)*self$clr()
history_tmp <- data.frame(
lr = k_get_value(self$model$optimizer$lr),
iterations = self$iteration,
avg_loss = smoothed_loss
)
self$history <- rbind(self$history, history_tmp)
k_set_value(self$model$optimizer$lr, lr)
}
)
)One Cycle Learning Policy
one_cycle_learn <- R6::R6Class(
"OneCycleLearning",
inherit = KerasCallback,
public = list(
max_lr = NULL,
min_lr = NULL,
div_factor = NULL,
moms = NULL,
pct_start = NULL,
batch_size = NULL,
n_train = NULL,
epochs = NULL,
max_mom = NULL,
min_mom = NULL,
a1 = NULL,
a2 = NULL,
clr_iterations = 0,
trn_iterations = 0,
history = data.frame(),
initialize = function(max_lr = 0.01,
div_factor= 25,
moms = c(0.85, 0.95),
pct_start = 0.3,
n_train = NULL,
epochs = 1,
batch_size = 16){
self$max_lr <- max_lr
self$min_lr <- max_lr/div_factor
self$max_mom <- moms[2]
self$min_mom <- moms[1]
self$pct_start = pct_start
self$n_train <- n_train
self$batch_size <- batch_size
n <- n_train/batch_size * epochs
self$a1 <- round(n * pct_start)
self$a2 <- n - self$a1
self$clr_iterations = 0
self$trn_iterations = 0
},
clr = function(){
if(self$clr_iterations <= self$a1){
return(
self$min_lr + (self$max_lr - self$min_lr) * self$clr_iterations/self$a1
)
}
if(self$clr_iterations > self$a1){
return(
self$min_lr/1e4 + 0.5 * (self$max_lr - self$min_lr/1e4) *
(1 + cos((self$clr_iterations - self$a1)/self$a2 * pi))
)
}
},
cm = function(){
if(self$clr_iterations <= self$a1){
return(
self$max_mom - (self$max_mom - self$min_mom) * self$clr_iterations/self$a1
)
}
if(self$clr_iterations > self$a1){
return(
self$max_mom - 0.5 * (self$max_mom - self$min_mom) *
(1 + cos((self$clr_iterations - self$a1)/self$a2 * pi))
)
}
},
on_train_begin = function(logs = list()){
if(self$clr_iterations == 0){
k_set_value(self$model$optimizer$lr, self$min_lr)
k_set_value(self$model$optimizer$beta_1, self$max_mom)
} else{
k_set_value(self$model$optimizer$lr, self$clr())
k_set_value(self$model$optimizer$beta_1, self$cm())
}
},
on_batch_end = function(batch, logs = list()){
self$trn_iterations = self$trn_iterations + 1
self$clr_iterations = self$clr_iterations + 1
lr = k_get_value(self$model$optimizer$lr)
beta_1 = k_get_value(self$model$optimizer$beta_1)
iterations = self$trn_iterations
history_tmp <- data.frame(
lr = lr,
beta_1 = beta_1,
iterations = iterations
)
self$history <- rbind(self$history, history_tmp)
k_set_value(self$model$optimizer$lr, self$clr())
k_set_value(self$model$optimizer$beta_1, self$cm())
}
)
)Na implementação com AdamW, no lugar de utilizar ciclos do parâmetro momentum do otimizador SGD, o parâmetro
beta_1varia durante o treinamento.↩